As an engineer at a rapidly growing startup, I found myself looking at an expensive logging system. We were heavily relying on Opensearch and Heroku’s Mezmo (formerly LogDNA) to handle all our logging needs. While these tools served us well, there was one major downside: the cost. At over $450 a month, maintaining such an infrastructure wasn’t sustainable for a fast-growing company looking to scale smartly. So, I took it upon myself to find a better, more cost-efficient solution that wouldn’t sacrifice performance.
That’s when I discovered Quickwit, and I knew this was the game-changer we needed.
Why Quickwit Became Our Secret Weapon
Quickwit caught my attention because it offered everything we needed: blazing-fast performance, scalability, and affordability. Built on top of the Tantivy search engine (written in Rust), it’s like Lucene but designed specifically for observability — something we needed in spades.
Taking charge of the project, I rolled up my sleeves and set out to rebuild our entire logging and observability pipeline around Quickwit and other opensource resources. And here’s why it’s been a game-changer for us:
1. Performance and Cost Efficiency: A Winning Combo
The first big win was getting rid of our bloated logging costs. By switching to Quickwit, we decoupled our storage from our compute needs, allowing us to store indexed data on S3-compatible object storage. This gave us three key benefits:
- Significantly Lower Costs: Quickwit’s log storage and indexing were far more affordable than our previous solutions.
- Seamless Scalability: As our data grew, Quickwit scaled effortlessly in our EKS setup, meaning no more sleepless nights worrying about log volumes or cost.
- Performance: Querying through massive datasets at breakneck speed became the norm — something our previous stack struggled with.
I had our new logging system up and running, delivering better performance and saving us a ton of money in the process.
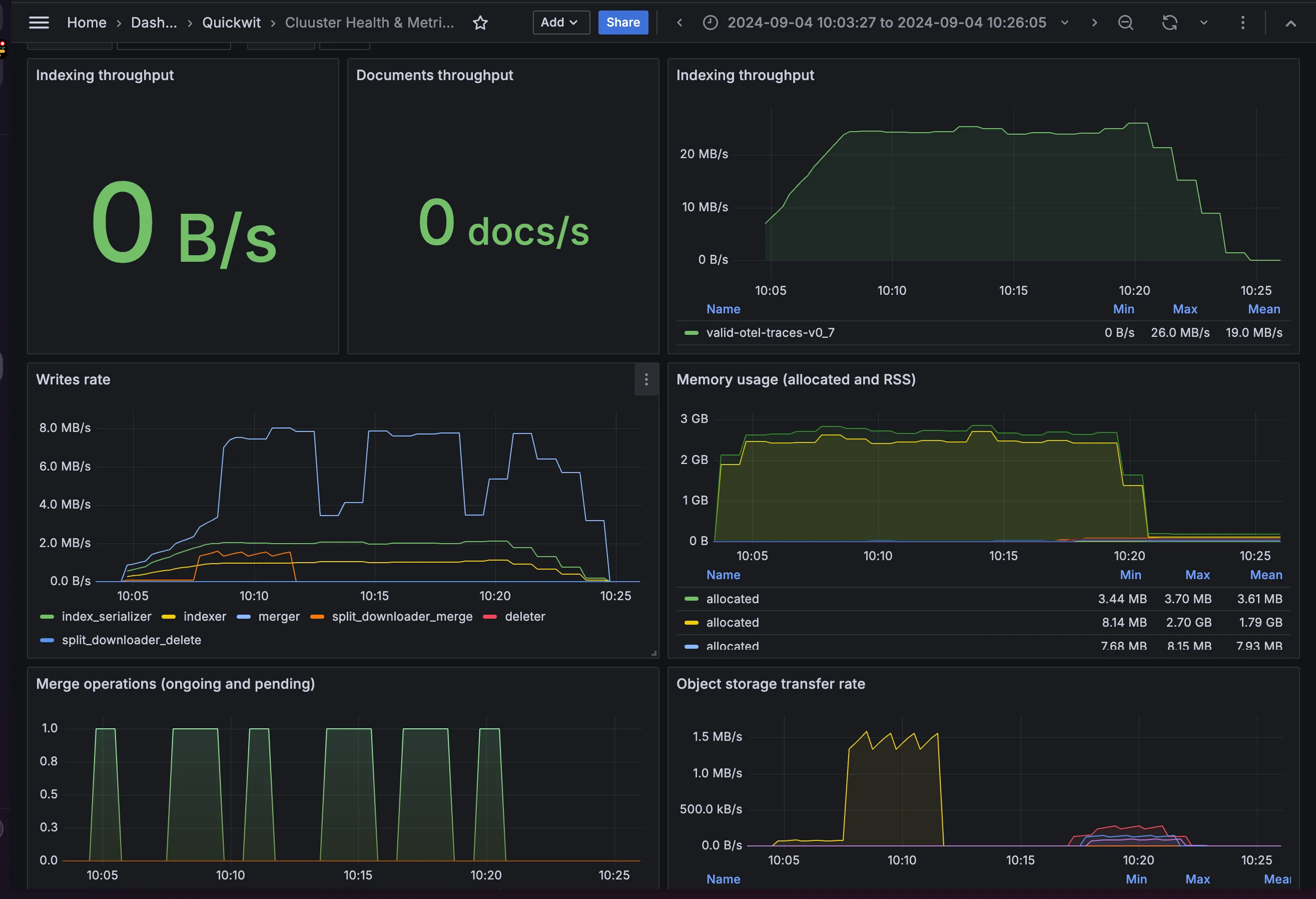
Performance metrics for large-scale ingestion using tracegen in Quickwit, as displayed on a Grafana dashboard.
2. Feature-Packed and Ready for Action
Once I had Quickwit set up, I was blown away by its versatility. Here are just a few of the features that made it the perfect fit:
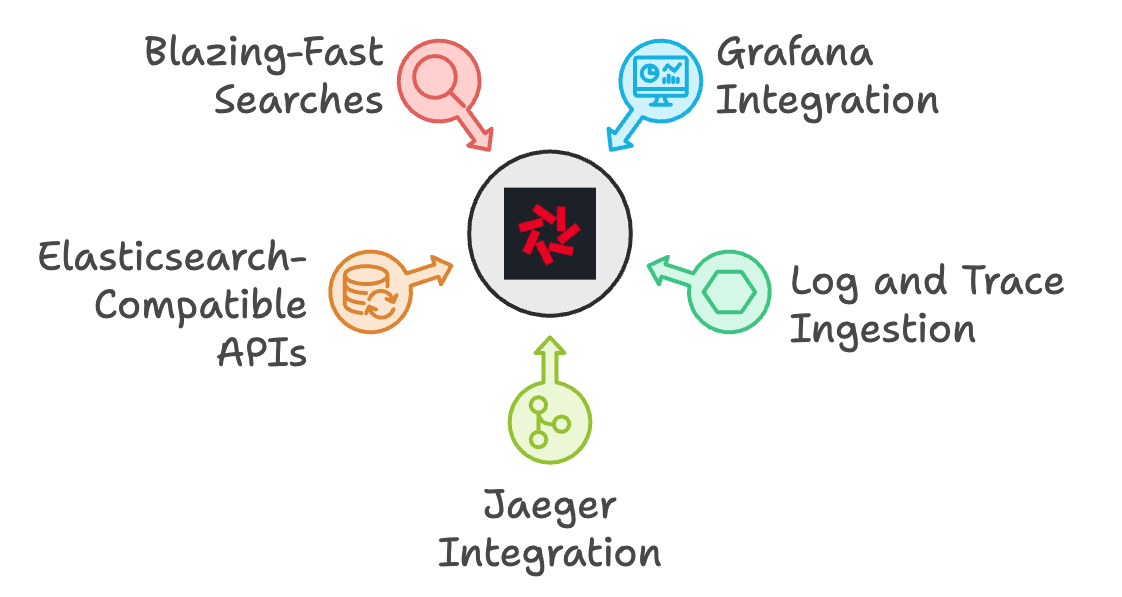
- Grafana Integration: With Quickwit’s Grafana datasource, I built dynamic, real-time dashboards that let us visualize everything in one place.
- Log and Trace Ingestion: Handling both logs and traces was a breeze, giving us a full picture of system performance.
- Jaeger Integration: Quickwit fit right into our existing distributed tracing setup with Jaeger, making debugging across services much easier.
- Elasticsearch-Compatible APIs: Migrating from OpenSearch was smooth, thanks to Quickwit’s Elasticsearch compatibility.
- Blazing-Fast Searches: We needed sub-second search performance for our growing datasets, and Quickwit delivered, letting us search logs directly from object storage without any delays.
3. Flexible Indexing for All Our Data
Quickwit’s flexibility really shined when I set it up to handle our semi-structured data. With schemaless indexing (introduced in version 0.8), I was able to index JSON documents with tons of varying fields, which was crucial for the different types of data that we handled. This adaptability saved us from having to restructure or compromise on how we log data.
4. Migrating Our Entire Pipeline: How We Did It
Migrating from our existing setup to Quickwit wasn’t just a switch — it was a full-scale overhaul. Here’s how I tackled it:
- Proof of Concept: First, I ran a small-scale test on an EC2 instance, comparing Quickwit’s performance against our existing tools. The results? Quickwit knocked it out of the park.
- Phased Migration: I began by moving non-critical log streams to Quickwit, allowing us to test its limits with larger datasets. Quickwit handled everything like a champ.
- Full Migration: Once I was confident in Quickwit’s capabilities, I completely transitioned the logging system over to Quickwit, finally shutting down our Mezmo and OpenSearch setups.
Challenges? You bet. Ensuring zero data loss during migration was the biggest hurdle. To overcome this, I ran dual pipelines during the transition, ensuring every single log was captured and fully indexed in Quickwit. No logs left behind!
5. Turbocharging Quickwit with Vector
To make our logging pipeline even more robust, I combined Quickwit with Vector — a logging powerhouse also written in Rust. Vector became the key to making sure our logs were not only ingested smoothly but also transformed and filtered along the way:
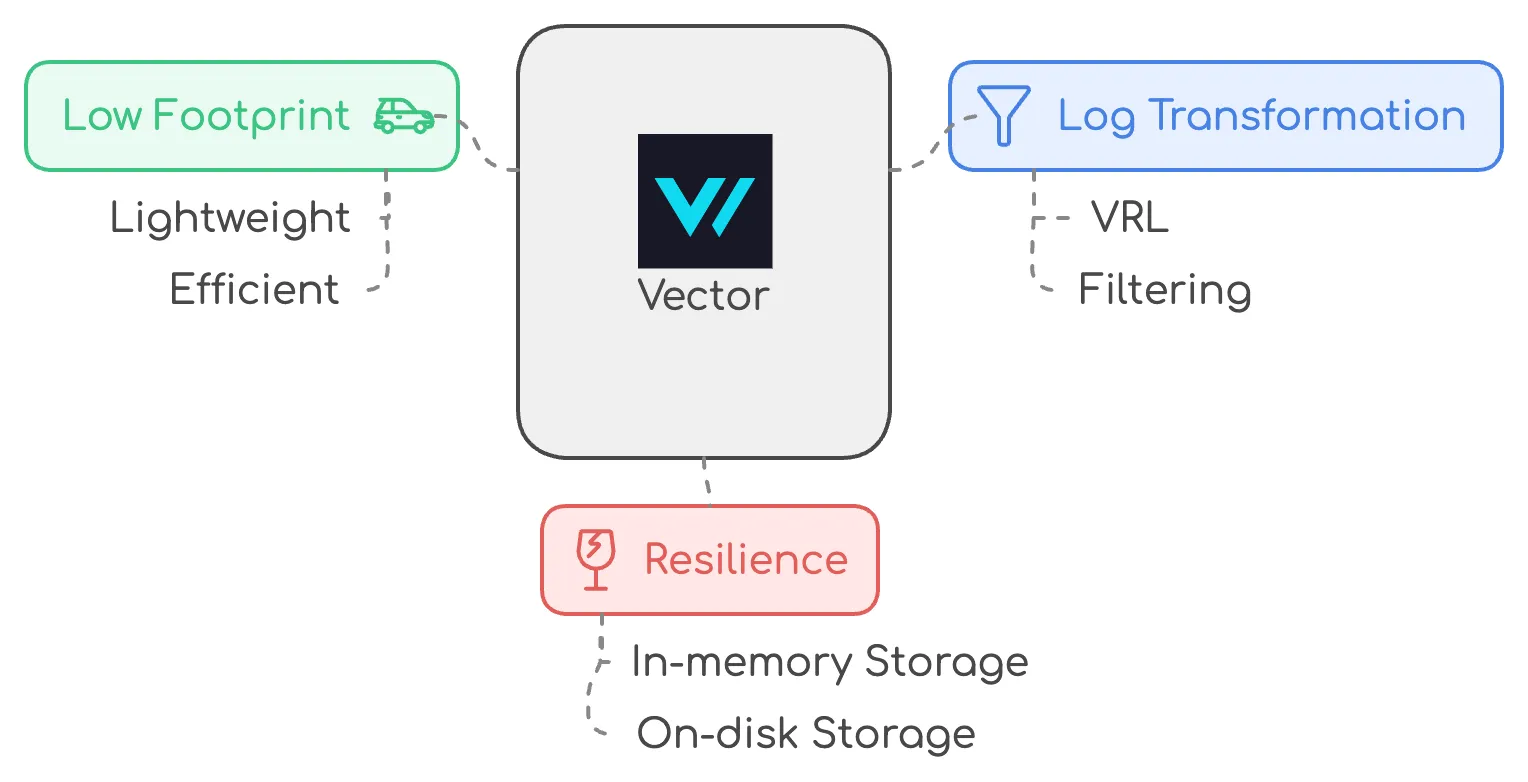
- Low Footprint: Vector is way lighter than Fluentbit or Logstash, making it the perfect complement to Quickwit.
- Log Transformation: With Vector Remap Language (VRL), I was able to filter and manipulate logs before they were stored, ensuring we only kept what was necessary and secure.
- Resilience: Vector offered in-memory and on-disk log storage when sinks weren’t available, ensuring no logs were ever lost, even in the event of a failure.
The Final Verdict
Building this entire observability solution with Quickwit has been one of the most rewarding challenges I’ve tackled. Not only did I dramatically reduce our costs, but I also significantly boosted our logging performance and flexibility. Quickwit has exceeded every expectation, and the transition from our old system to this new setup was seamless.
If you’re a startup or a tech team looking for an observability tool that’s both powerful and cost-effective, give Quickwit a look. It might just be the solution you’ve been searching for.
Catch you next time!